
Face Dataset
In my undergraduate thesis research, I wanted to study race-related biases in face memory, with a high degree of experimental and psychophysical control. I had three key criteria:
- Broad Sampling: Faces must sample thoroughly from a wide array of appearances, ages, and race-related features.
- Multi-Angle Imaging: Faces must be imaged from different angles to test the ability to generalize across viewpoints.
- Low-Level Control: Face images must be well controlled for luminance, viewing angle, and other low-level cues.
I deciding to create my own dataset, using the MUCT Face Database as a starting point.
Methods
I used FaceBuilder for Blender to manually landmark multi-viewpoint MUCT images.
This created a 3D mesh and texture for each face, which could then be rotated and imaged under controlled lighting conditions.
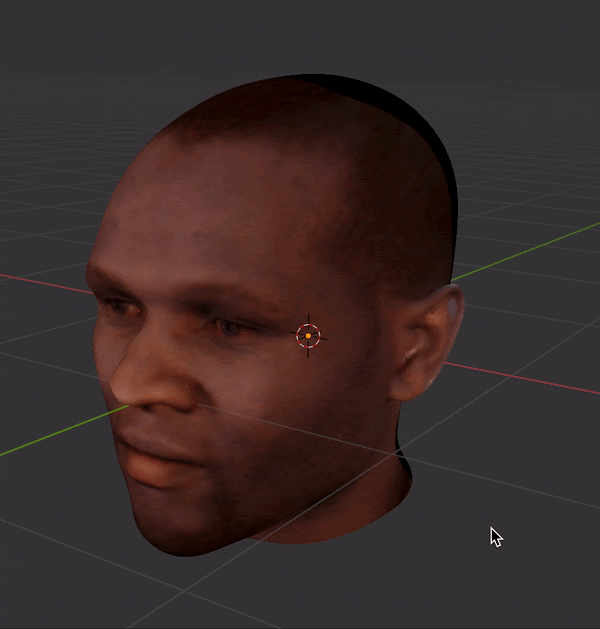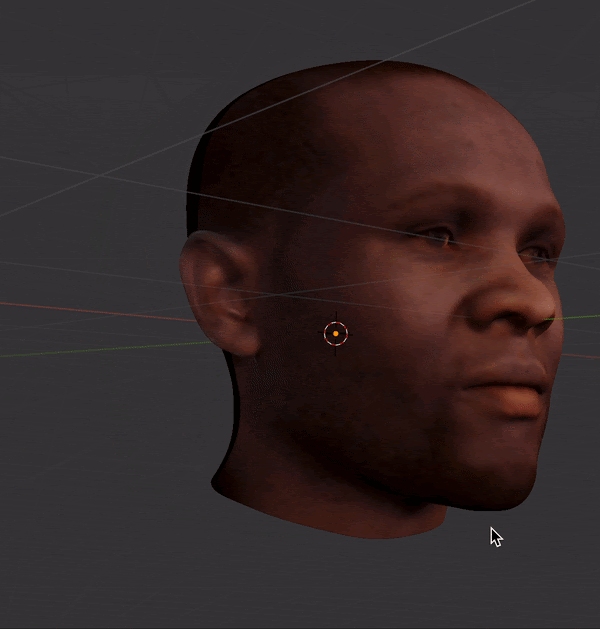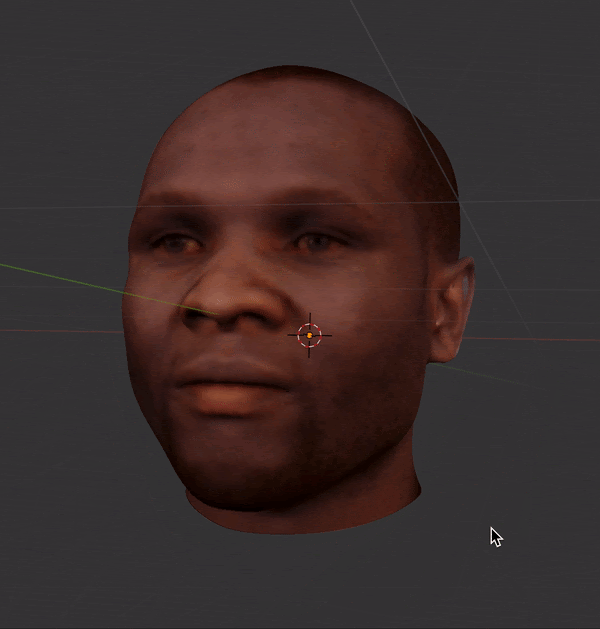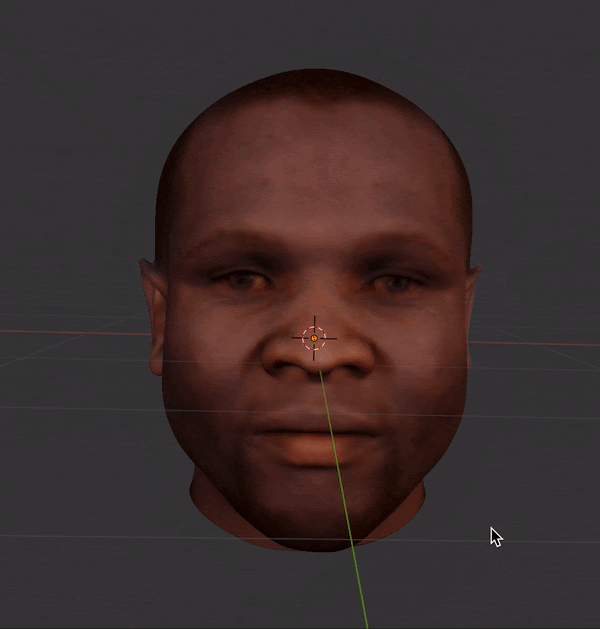
Finally, I produced grayscale and luminance-matched images across 15 angles (5x3 grid of viewpoints).
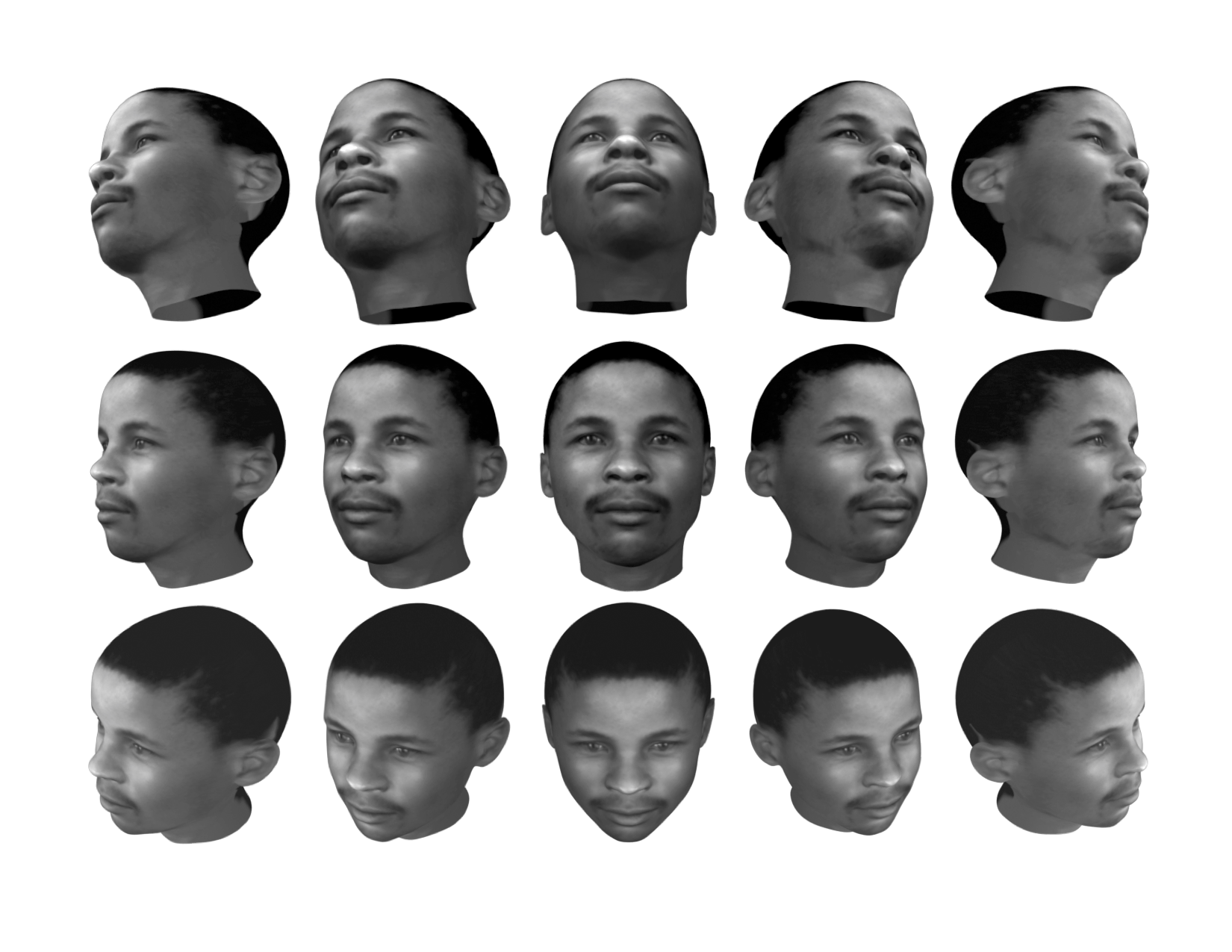
Dataset
The dataset is available on GitHub. It contains 156 individuals and is organized into 3D meshes, textures, grayscale/luminance-matched imagery, and processing notes.
Behavioral Data (on request)
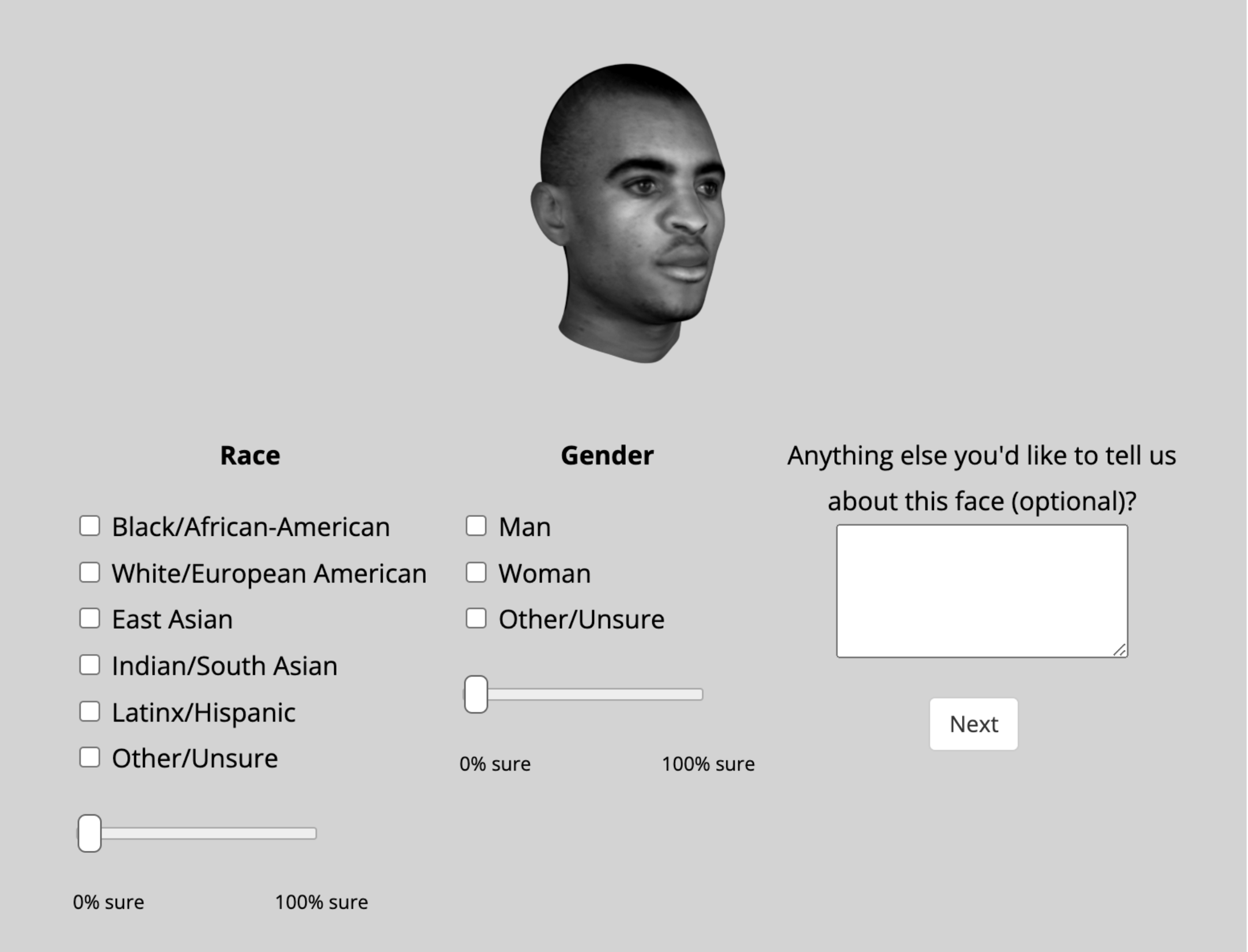
1. Classification task: behavioral data from 241 online participants providing population-level estimates of perceived racial and gender characteristics.
2. Perception-memory task: data from 135 participants performing dynamic oddity and recognition memory tests.

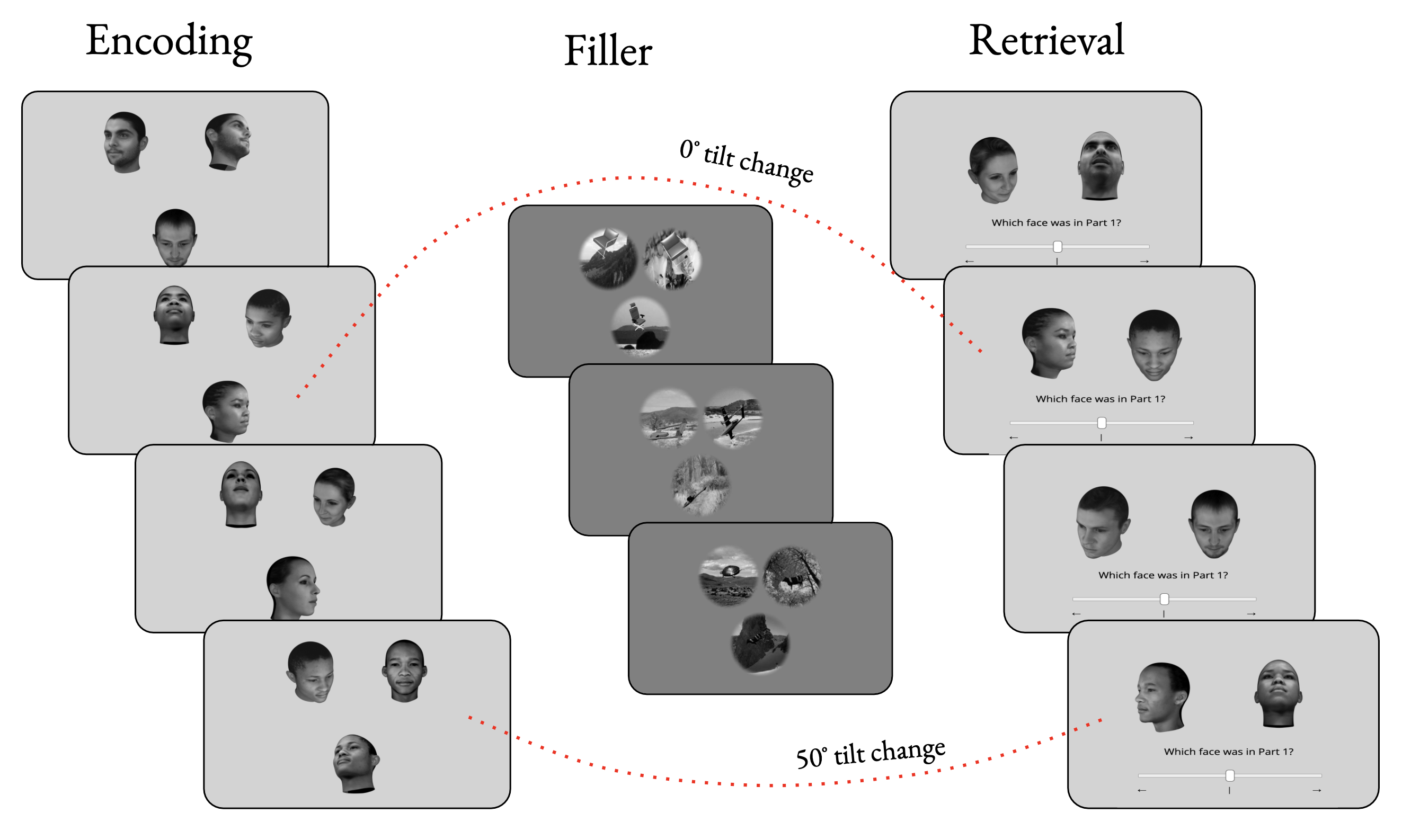
All data are available via email request.